
[TOC]
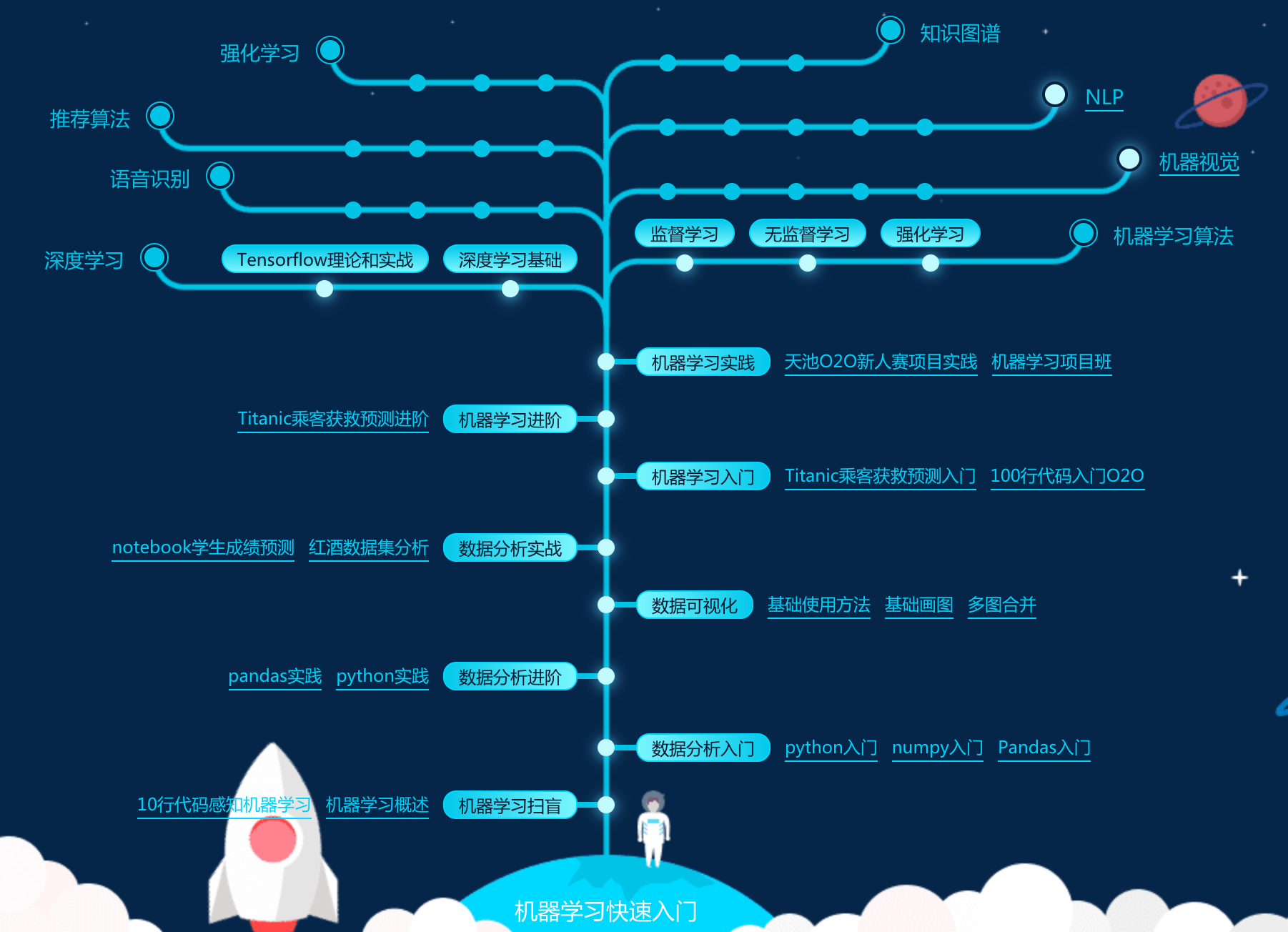
机器学习
学习需要从锻炼中成长;
机器学习概述10行代码感知机器学习 机器学习扫盲
数据分析入门 python入门 numpy入门 Pandas入门
python实践 pandas实践 数据分析进阶
数据可视化 基础使用方法 基础画图 多图合并
红酒数据集 分析notebook学生成绩预测 数据分析实战
机器学习入门 Titanic乘客获救预测入门 100行代码入门O2O
Titanic乘客获救预测进阶 机器学习进阶
机器学习实践 天池O2O新人赛项目 实践机器学习项目班
深度学习基础 Tensorflow理论和实战 监督学习 无监督学习 机器视觉 NLP 强化学习
深度学习 机器学习算法 强化学习 推荐算法 语音识别 知识图谱

天池
到2019-09-20
2019广东工业智造创新大赛
人工智能是国家战略性新兴产业。随着广东制造产业信息建设的不断完善,且产业布局较为完整,诞生了一批信息化程度高的工业制造企业,已沉淀积累了一定数据资源。2019年广东省人民政府联合阿里巴巴集团共同启动“广东工业智造创新大赛”,聚焦布匹疵点智能识别和面料剪裁利用率优化,旨在通过数据开放召集全球众智,将重点围绕工业制造大数据展开,以落地为导向,聚集全球顶级人才,发掘全球先进的智能制造应用成果,推动人工智能技术在广东纺织行业的探索与发展,用技术驱动广东智能制造产业转型升级和变革发展。
赛场一:布匹疵点 智能识别
竞赛课题
布匹疵点检验是纺织行业生产和质量管理的重要环节,人工智能和计算机视觉技术 应用于纺织行业,其价值无疑是巨大的。本赛场聚焦布匹疵点智能检测,要求选手研究开发高效可靠的计算机视觉算法,提升布匹疵点检验的准确度,降低对大量人工的依赖,提升布样疵点质检的效果和效率。初赛阶段考察素色布瑕疵检测和分类能力,复赛阶段考察花色布的瑕疵检测和分类能力。
布匹疵点检验是纺织行业生产和质量管理的重要环节,而布匹疵点智能检测是困扰行业多年的技术瓶颈。目前几乎都是人工检测,易受主观因素影响,缺乏一致性;并且检测人员在强光下长时间工作对视力影响极大。借助人工智能和计算机视觉 等先进技术,实现布匹疵点智能检测,其价值无疑是巨大的。
数据描述 深入佛山南海纺织车间现场采集布匹图像,制作并发布大规模的高质量布匹疵点数据集,同时提供精细的标注来满足算法要求。其中,素色布数据约8000张,花色布数据约12000张。
https://github.com/lambda-xmu
使用torchvision(0.3.0),像训练分类模型一样训练检测模型 baseline模型
torchvision在0.3.0版本中集成了Facebook Research检测框架 maskrcnn_benchmark,不用额外编译库,纯python实现,让检测任务更简单,像处理分类任务一样。
本notebook对torchvision detection 训练入口做了部分删减,使更容易理解。
训练环境
- pytorch 1.1.0
- torchvison 0.3.0
- 单卡训练
论坛
https://tianchi.aliyun.com/competition/entrance/231748/forum
学习资料
https://tianchi.aliyun.com/competition/entrance/231748/learn
https://tianchi.aliyun.com/course/video?spm=5176.12586971.1001.1.61376448KdAkgB&liveId=41083
模型训练 1.torchvision detection数据dataset采用coco格式,先使用Fabric2COCO转换脚本将数据转换为coco格式。
2.训练入口文件为train.py,train.py包含几部分:(1)生成data_loader &dataset; (2)建立model; (3)创建optimizer&&lr_scheduler;(4)training,整个代码结构与分类基本相似
3.前传文件为inference.py
赛场二:面料剪裁利用率优化
竞赛课题
面料切割利用率的提升是纺织行业长期追求的目标。如何提升面料切割利用率,既是企业生产精益化的难点,也是痛点。当前纺织行业布匹原材料的成本占到40%左右,价值较高。本赛场要求选手开发算法模型,实现在较短时间范围内计算获得高质量可执行的排版结果,减少切割中形成的边角废料,提升面料切割利用率,减少计划时间、提高工作效率和避免人工计算的失误,提升价值降低成本。。
在切割之前,需要确定多个零件在面料上的位置和角度,再充分利用零件在形状上的互补特征,对零件排布的方式进行优化。面料切割问题的特性,是零件存在多种尺寸、形状,比如用作衬衫制作的袖子、后背等零件,用来切割的布匹本身存在多类瑕疵,如破洞、折皱、漏纱等,在排版中需要避开。此外,某些订单,对零件存在个性化排版需求,因此在下料环节中,需要依照订单要求进行排版下料。当前纺织行业布匹原材料的成本占到40%左右,价值较高。
数据描述 数据由广东瑞洲科技有限公司提供。比赛每阶段将提供2-3个批次的零件数据及面料数据,1个批次约200-400个零件数据,用于模型算法的研发和测试。同时,会提供零件排版的约束要求,比如满足零件旋转角度、面料瑕疵、最小间距等。
kaggle competitions
kaggle比赛kaggle competitions

由墨尔本大学的Anthony Goldbloom创办,是最早的大数据竞赛平台,拥有庞大的技术分享社区和众多开元代码,面向全球用户;产品2010年上线,累计举办竞赛260+个(含练习赛和自办赛),注册用户数20W+。

Sortable and searchable compilation of solutions to past Kaggle competitions.
下表只列出过去半年内active的competitons,并且按照recently created排序。
数据竞争
包括数据竞争笔记,顶级解决方案分析等。
数据竞争从0到1
- 数据竞争从0到1第一部分:信用欺诈检测器
- EDA(探索性数据分析)
- 不平衡
- 度量
- 重采样
- 交叉验证
- 数据竞争从0到1第二部分:特征工程
- 数据竞争从0到1第二部分:特征工程(补充)
EDA&基线
效用
environment
环境
yml脚本;
name: mne外资企业
- channels:渠道:——默认值
- defaults
- dependencies:依赖关系
- python>=3.6
- pip
- mkl
- numpy
- scipy
- matplotlib
- pyqt>=5.9
- vtk>=8
- pandas
- scikit-learn
- h5py
- pillow
- statsmodels
- jupyter
- nose
- pytest
- pytest-cov
- sphinx
- joblib
- psutil
- numpydoc
- flake8
- spyder
- numexpr
- pip:
- mne
- “https://api.github.com/repos/enthought/traits/zipball/a99b3f64d50c5f7f28ffc01bf69419b061f9e976”
- “https://api.github.com/repos/enthought/pyface/zipball/6a0cac149d56293482bb828a7d98122667c773be”
- “https://api.github.com/repos/enthought/traitsui/zipball/e366ad3886d3c39bedb96e83bab447d31c4ab725”
- “https://api.github.com/repos/enthought/mayavi/zipball/master”
- “https://api.github.com/repos/nipy/PySurfer/zipball/master”
- nitime
- nibabel
- nilearn
- neo
- pytest-sugar
- pytest-faulthandler
- pydocstyle
- sphinx_bootstrap_theme
- “https://api.github.com/repos/sphinx-gallery/sphinx-gallery/zipball/master”
- python-picard
game
Table of contents 表的内容
Kaggle(新)
天池(新)
DrivenData
CodaLab(新)
Challenge Data
crowdAI(新)
Numer.ai
[SIGNATE](#signate)(新)
Unearthed(新)
Analytics Vidhya
TechGig
HackerEarth
NIPS 2018 Competition Track
GECCO 2018 Competition
Grand Challenges in Biomedical Image Analysis
Kelvins
Unrestricted Adversarial Examples Challenge (不受限对抗样本挑战)
A Conversational Question Answering Challenge (CoQA)
The Stanford Question Answering Dataset (SQuAD2.0)
The Scene Understanding and Modeling Challenge (SUMO)
Open MIC
The SpaceNet Challenge Round 4
Online Data-Driven Multi-Objective Optimization
AI Challenger 全球AI挑战赛2018
IDAO.world – International Data Analysis Olympiad 全球数据分析大赛(新)
MC挑战赛
NIST: Differential Privacy Synthetic Data Challenge (NIST: 综合数据差分隐私挑战)
Yaw Alignment Marathon Challenge (风力涡轮机偏航失准角挑战)
JData
JDDiscovery(新)
点石(新)
TinyMind
Kesci
DataCastle(新)
Biendata
DataFountain
逾期的
第二届易观算法大赛 | 数愿 | 第3届 融360金融算法挑战赛
GeekPwn 2018 国际安全极客大赛 | 对抗样本攻防赛CAAD
2018年国际大学生类脑计算创新应用大赛 | 深圳医疗健康大数据创新应用国际大赛
华为大数据平台 | 2018讯飞AI开发者大赛
ATEC人工智能大赛(蚂蚁金服)
中国法研杯司法人工智能挑战赛
Visual Dialog Challenge 2018
The FashionGen Challenge | 京东AI时尚挑战赛 | 京东JD Dialog Challenge人机对话挑战赛
COLIEE-2018
第三届魔镜杯大赛 | CoNaLa: The Code/Natural Language Challenge
Momenta Car Detection Challenge (MCDC) | 北京市高校校园大数据竞赛
OpenAI 迁移学习竞赛 | CoNLL–SIGMORPHON 2018 Shared Task
智慧金融马上AI全球挑战者大赛 | 第六届-泰迪杯数据挖掘挑战赛
CCDM-2018 | 2018机器阅读理解技术竞赛 | 第二届"讯飞杯"中文机器阅读理解评测
SODA | 数据嗨客 | 竞技乎 | 知数学院 | 第三届数据新闻比赛
数据竞赛Tricks
技巧
2019年下半年对我触动很大的两个知识分享是:
- 志峰现场讲解的《Tricks in Data Mining Competitions 》
- 鱼佬知识星球分享的《Kaggle数据竞赛知识体系》
1 数据竞赛的流程
这是老生常谈的话题:数据分析主要目的是分析数据原有的分布和内容;特征工程目的是从数据中抽取出有效的特征;模型训练与验证部分包括数据划分的方法以及数据训练的方法;模型融合部分会简介模型融合的方法和实现方式。
我想表达的是:虽然数据挖掘在流程上可以看成是瀑布式的,但各个流程相互影响:比如数据分析可以挖掘出数据的分布规律,可以指导特征工程;特征的验证又可以反馈数据分析的结果。所以在实际比赛过程中这个流程是反复循环的,并不是一蹴而就的。
一个特征不是拍脑袋想的,其最开始从EDA发现的,然后通过模型本地CV和线上PB得分进行验证。所以我对比赛的baseline代码分享一向比较谨慎,一是baseline是最终的代码并不能包括失败的尝试;二是很多选手并不会跑baseline代码只是为了排名,并不会尝试去理解代码的逻辑。在数据竞赛流程上比较重要的一点是:你要知道你现在处于哪一个步骤,下一步应该做什么,还有哪些TODO和改进的地方。
1.1 数据分析
在拿到数据之后,首先要做的就是要数据分析(Exploratory Data Analysis,EDA)。数据分析是数 据挖掘中重要的步骤,同时也在其他阶段反复进行。可以说数据分析是数据挖掘中至关重要的一步,它给之后的步骤提供了改进的方向,也是直接可以理解数据的方式。
拿到数据之后,我们必须要明确以下几件事情:
- 数据是如何产生的,数据又是如何存储的;
- 数据是原始数据,还是经过人工处理(二次加工的);
- 数据由那些业务背景组成的,数据字段又有什么含义;
- 数据字段是什么类型的,每个字段的分布是怎样的;
- 训练集和测试集的数据分布是否有差异;
在分析数据的过程中,还必须要弄清楚的以下数据相关的问题:
- 数据量是否充分,是否有外部数据可以进行补充;
- 数据本身是否有噪音,是否需要进行数据清洗和降维操作;
- 赛题的评价函数是什么,和数据字段有什么关系;
- 数据字段与赛题标签的关系;
以上细节可能在部分赛题中非常有必要,但具体操作是否有效还是要具体进行尝试。
1.2 赛题背景分析
在进行数据分析步骤前后,我们还需要对赛题的背景进行理解。赛题背景分析能够帮助我们理解赛题的任务,以及赛题数据的收集和评价方法。当然有些赛题的业务逻辑比较简单,容易理解;但有一些赛题的业务逻辑经过匿名处理,就会导致很难对赛题进行理解。
无论出题方给定了多少赛题介绍,参赛选手还是要自己从新理解一遍赛题,这样可以加深赛题的印象。有很多时候,赛题的一些细节会直接影响到最后的精度,而这些关键的细节是需要人工发现的。
总的说来赛题背景分析包括以下细节:
- 赛题业务场景是什么,数据是如何产生的,数据标签如何得来的?
- 赛题任务是什么,具体要解决的问题是如何定义的;
- 赛题任务是否有对应的学术任务?
在赛题背景分析步骤中最重要的是分析赛题是什么任务,赛题任务是什么问题,历史是否有类似的赛题,学术上是否有对应的问题。如果历史有类似的比赛/学术上对应的问题,那么直接copy解决方案来就OK了。
1.3 数据清洗
数据清洗步骤主要是对数据的噪音进行有效剔除。数据噪音可能有多个来源,来源于数据本身,来源于数据存储,或来源于数据转换的过程中。因为噪音会影响特征,也会影响最后的模型结果,因此数据清洗是非常有必要的。
数据清洗可以从以下几个角度完成:
- 对于类别变量,可以统计比较少的取值;
- 对于数字变量,可以统计特征的分布异常值;
- 统计字段的缺失比例;
1.4 特征预处理
特征预处理包括如下内容:
-
量纲归一化:标准化、区间放缩
-
特征编码:
-
-
对于类别特征来说,有如下处理方式:
-
- 自然数编码(Label Encoding)
- 独热编码(Onehot Encoding)
- 哈希编码(Hash Encoding)
- 统计编码(Count Encoding)
- 目标编码(Target Encoding)
- 嵌入编码(Embedding Encoding)
- 缺失值编码(NaN Encoding)
- 多项式编码(Polynomial Encoding)
- 布尔编码(Bool Encoding)
-
对于数值特征来说,有如下处理方式:
-
- 取整(Rounding)
- 分箱(Binning)
- 放缩(Scaling)
-
-
缺失值处理
-
- 用属性所有取值的平均值代替
- 用属性所有取值的中位数代替
- 用属性所有出现次数最多的值代替
- 丢弃属性缺失的样本
- 让模型处理缺失值
这一部分内容可以参考这个PPT:
https://www.slideshare.net/HJvanVeen/feature-engineering-72376750
1.5 特征工程
特征工程与EDA联系紧密,可以说是EDA具体的操作吧。因为数据分析本身就是“假设”-“分析”-“验证”的过程,这个验证的过程一般是指构建特征并进行本地CV验证。
可以从一下几个角度构建新的特征:
- 数据中每个字段的含义、分布、缺失情况;
- 数据中每个字段的与赛题标签的关系;
- 数据字段两两之间,或者三者之间的关系;
特征工程本质做的工作是,将数据字段转换成适合模型学习的形式,降低模型的学习难度。
2 结构化数据技巧
常规的特征工程已经人人都会,不过我还是建议可以学习AutoML的一些操作,互补学习下。至少在结构化数据领域,常见的操作它都会。
在结构化数据中,针对不同的赛题任务有不同的magic feature。比如用户违约风控类赛题需要考虑用户信息的交叉编码,用户流程等CTR类型赛题可以考虑target encoding,回归类赛题可以对对赛题目标进行标准化。如果赛题类型已知,则可以优先用此类方法进行求解。
如果赛题是匿名数据挖掘,则需要煎饼果子啥都来一套了(任何操作都试试)。此外在匿名数据和多模态数据赛题中,可以尝试下降噪自编码器。
3 非结构化数据技巧
非结构化数据一定要找准baseline,一定要找准base model。
3.1 视觉类型任务
常见的视觉任务包括:
- 图像分类(ImageClassification)
- 图像检索(Image)
- 物体检测(ObjectDetection)
- 物体分割(ObjectSegmentation)
- 人体关键点识别(PoseEstimation)
- 字符识别
OCR(OpticalCharacterRecognition)
如果是简单的分类任务,可以直接手写CNN分类模型;如果是物体检测、图像分割、人体关键点检测、人脸识别等,优先找成熟的框架和模型。都9012年了,学深度学习不要只会分类。
在视觉类型赛题中,数据扩增非常重要,具体的数据扩增方法与具体的赛题相关。找好base model,找好数据扩增方法,基本上成功了一半。
3.2 文本类型任务
文本任务我不太熟,我只会BERT。文本任务设计到的技巧有:
- TFIDF
- 词向量
- GPU
在这个bert满天飞的时期,大家一定要保持对技术的耐心。不要只会bert,盲目的使用bert。bert虽然很好,但NLP的基础不能跳过不学。
在炼丹过程中还有一些细节需要考虑,比如参数初始化、batch size、优化器、未登录词的处理和网络梯度裁剪等,这些都是要自己根据任务进行总结的。
4 如何选择一个合适的数据竞赛?
最后我想聊聊如何选择一个合适的赛题。现在数据科学竞赛非常多,国内外大大小小的企业都可以组织各种类型的数据科学竞赛。竞赛多 了可选择的机会也多了,但对于每个参赛选手来说我们的时间和精力是有限的,所以选择一个合适的竞赛参赛就至关重要了。这里的合适的含义带有一定的主观色彩,我会从竞赛内容和个人收获两个方面来阐述。
首先数据竞赛的形式非常多:有的赛题要求选手开发应用,有的要求选手设计优化算法,有的要求选手提出解决方案。选择赛题一定要选择自己擅长或者想学习的赛题,一定要选择尽量靠谱公平的赛题(国内比赛偶尔会出现名次内定的情况)。此外还要根据具体的赛题日程和规则进行衡量,尽量选择日程安排比较紧凑合理的赛题,尽量选择换排行榜(切换不同测试集重新排名)的赛题。
此外赛题中也有不同的赛题类型,有结构化、语音、图像、视频和文本不同类型的。我期望大家是尽量能够多参加不同类型的赛题,不要受到数据形式的限制,多接触各种类型的算法和知识。其实很多知识点都是类似的,在语音识别和语音分类中的特征提取操作或许能够用在某些结构化数据上,CNN 操作也经常用在语音分类上,序列数据通常可以用词向量来编码。
此外由于数据竞赛本身具有一定的随机性(数据噪音、算法的随机性和优化过程的随机性),导致不同选手使用相同的数据和相同代码得到的结果在精度上都有差异。举个例子在 XGBoost 算法中有很多超参数可以调节,而不同的超参数可能会带来一定的精度差异。我建议大家尽量参加不是由随机性主导排名的比赛,尽量参加随机性小一点的竞赛。
最后还可以从赛题的奖励和赛制进行选择,我个人比较倾向于 TOP10 都有钱的比赛,同时国内比赛都有现场答辩的环节,所以比赛答辩城市也可以考虑下。
他山之石
kaggle
官方网址:https://www.kaggle.com/
开放数据集:
https://www.kaggle.com/datasets
Kaggle Competition Past Solutions=Kaggle竞争过去的解决方案
http://www.chioka.in/kaggle-competition-solutions/
Winning solutions of kaggle competitions=卡格尔竞赛获奖方案SRK https://www.kaggle.com/sudalairajkumar/winning-solutions-of-kaggle-competitions
Kaggle 项目实战(教程)
https://github.com/apachecn/kaggle
ApacheCN:http://www.apachecn.org
Kaggle过去的解决方案
http://ndres.me/kaggle-past-solutions/




