
数据分析data analysis
基于网站数据分析
“网站体系-数据分析”
工具
python、pandas、numpy
图表
1.堆积图
2.折线图
3.饼状图
4.散点图
5.折线图
6.一个图3条线
数据集data
淘宝
淘宝卖家

直方图
import pandas as pd
import matplotlib.pyplot as plt
df = pd.DataFrame({'lab':['A', 'B', 'C'], 'val':[10, 30, 20]})
ax = df.plot.bar(x='lab', y='val', rot=0)
双色
speed = [0.1, 17.5, 40, 48, 52, 69, 88]
lifespan = [2, 8, 70, 1.5, 25, 12, 28]
index = ['snail', 'pig', 'elephant', 'rabbit', 'giraffe', 'coyote', 'horse']
df = pd.DataFrame({'speed': speed, 'lifespan': lifespan}, index=index)
ax = df.plot.bar(rot=0)
奇异矩阵
#在Numpy中有一个称为线性代数linalg的线性代数工具箱
奇异矩阵
from numpy import *
from numpy import linalg as la
df = mat(array([[1,1],[2,2],[0,0]]))
U,Sigma,VT = la.svd(df)
print(U)
# [[ 0.16018224 0.98708746]
# [ 0.98708746 -0.16018224]]
print(Sigma)
# [7.16227766 0.83772234]
print(VT)
# [[ 0.16018224 0.98708746]
# [ 0.98708746 -0.16018224]]
plt.show绘制图形不显示问题
https://www.jianshu.com/p/3f4b89aaf057(临时的方法有用)
import matplotlib.pyplot as plt
之前加入这两行代码:
import matplotlib
matplotlib.use('Qt5Agg')
绘图的时候出现一些信息
import warnings
warnings.filterwarnings('ignore')
# 高斯混合模型
# 下面 plt.show绘制图形不显示问题
# import matplotlib
# matplotlib.use('Qt5Agg')
#不好用 跳出来显示。
# 绘图的时候出现一些信息
# import warnings
# warnings.filterwarnings('ignore')
Numpy中ndim、shape、dtype、astype的用法
1. ndim返回的是数组的维度,返回的只有一个数,该数即表示数组的维度。
2. shape:表示各位维度大小的元组。返回的是一个元组。
对于一维数组:有疑问的是为什么不是(1,6),因为arr1.ndim维度为1,元组内只返回一个数。
对于二维数组:前面的是行,后面的是列,他的ndim为2,所以返回两个数。
对于三维数组:很难看出,下面打印arr3,看下它是什么结构。
先看最外面的中括号,包含[[1,2,3],[4,5,6]]和[[7,8,9],[10,11,12]],假设他们为数组A、B,就得到[A,B],如果A、B仅仅是一个数字,他的ndim就是2,这就是第一个数。但是A、B是(2,3)的数组。所以结合起来,这就是arr3的shape,为(2,2,3)。
将这种方法类比,也就可以推出4维、5维数组的shape。
3. dtype:一个用于说明数组数据类型的对象。返回的是该数组的数据类型。由于图中的数据都为整形,所以返回的都是int32。如果数组中有数据带有小数点,那么就会返回float64。
有疑问的是:整形数据不应该是int吗?浮点型数据不应该是float吗?
解答:int32、float64是Numpy库自己的一套数据类型。
s.astype('int')
4. astype:转换数组的数据类型。
int32 --> float64 完全ojbk
float64 --> int32 会将小数部分截断
string_ --> float64 如果字符串数组表示的全是数字,也可以用astype转化为数值类型
注意其中的float,它是python内置的类型,但是Numpy可以使用。Numpy会将Python类型映射到等价的dtype上。
商家管理系统
淘宝网
https://i.taobao.com/my_taobao.htm?spm=a21bo.2017.1997525045.1.5af911d9UzJihQ
支付宝商家
https://mrchportalweb.alipay.com/user/home.htm#/
阿里云官网
https://www.aliyun.com/?spm=5176.13203013.fnqwg5agi.2.2ec731f9zcm6aT&aly_as=0xnI35w
口碑商家中心-支付宝
https://e.alipay.com/material/printableMaterials.htm
阿里云大学
https://market.aliyun.com/products/57252001/cmgj021471.html?spm=5176.11778031.dnewclick.ddawen.83f62bb48EoHmq&aly_as=-yoGXAE#sku=yuncode1547100001
数据库网关
数据库网关(Database Gateway, DG)允许您无需本地开通公网端口,将本地数据库与云服务连接起来。数据库网关可以与阿里云的产品(例如,数据传输服务 DTS,数据库备份 DBS,数据管理 DMS)集成使用,目前提供免费的私网数据库接入能力。
阿里云大学Apsara Clouder专项技能认证:实现调用API接口
API是一组封装好的函数,通过API,你可以为应用快速扩展功能,而无需理解它们是如何实现的,从而提升开发效率。通常,API服务商会提供API文档,如何根据文档来使用API呢?本认证助你GET相关技能。
ECharts图
百度的ECharts目前在国内使用的比较多,所以总结了一些相关知识;官网地址,详细的可以参考:http://echarts.baidu.com/index.html
特性介绍
ECharts,一个纯 Javascript 的图表库,可以流畅的运行在 PC 和移动设备上,兼容当前绝大部分浏览器(IE8/9/10/11,Chrome,Firefox,Safari等),底层依赖轻量级的 Canvas 类库 ZRender,提供直观,生动,可交互,可高度个性化定制的数据可视化图表。
ECharts 3 中更是加入了更多丰富的交互功能以及更多的可视化效果,并且对移动端做了深度的优化。
获取 ECharts
你可以通过以下几种方式获取 ECharts。
- 从官网下载界面选择你需要的版本下载,根据开发者功能和体积上的需求,我们提供了不同打包的下载,如果你在体积上没有要求,可以直接下载完整版本。开发环境建议下载源代码版本,包含了常见的错误提示和警告。
- 在 ECharts 的 GitHub 上下载最新的
release版本,解压出来的文件夹里的dist目录里可以找到最新版本的 echarts 库。 - 通过 npm 获取 echarts,
npm install echarts --save,详见“在 webpack 中使用 echarts” - cdn 引入,你可以在 cdnjs,npmcdn 或者国内的 bootcdn 上找到 ECharts 的最新版本。
引入 ECharts
ECharts 3 开始不再强制使用 AMD 的方式按需引入,代码里也不再内置 AMD 加载器。因此引入方式简单了很多,只需要像普通的 JavaScript 库一样用 script 标签引入。
<!DOCTYPE html>
<html>
<header>
<meta charset="utf-8">
<!-- 引入 ECharts 文件 -->
<script src="echarts.min.js"></script>
</header>
</html>
绘制一个简单的图表
在绘图前我们需要为 ECharts 准备一个具备高宽的 DOM 容器。
<body>
<!-- 为 ECharts 准备一个具备大小(宽高)的 DOM -->
<div id="main" style="width: 600px;height:400px;"></div>
</body>
然后就可以通过 echarts.init 方法初始化一个 echarts 实例并通过 setOption 方法生成一个简单的柱状图,下面是完整代码。
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>ECharts</title>
<!-- 引入 echarts.js -->
<script src="echarts.min.js"></script>
</head>
<body>
<!-- 为ECharts准备一个具备大小(宽高)的Dom -->
<div id="main" style="width: 600px;height:400px;"></div>
<script type="text/javascript">
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 指定图表的配置项和数据
var option = {
title: {
text: 'ECharts 入门示例'
},
tooltip: {},
legend: {
data:['销量']
},
xAxis: {
data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]
},
yAxis: {},
series: [{
name: '销量',
type: 'bar',
data: [5, 20, 36, 10, 10, 20]
}]
};
// 使用刚指定的配置项和数据显示图表。
myChart.setOption(option);
</script>
</body>
</html>
这样你的第一个图表就诞生了!
在 webpack 中使用 ECharts
Webpack 是目前比较流行的模块打包工具,你可以在使用 webpack 的项目中轻松的引入和打包 ECharts,这里假设你已经对 webpack 具有一定的了解并且在自己的项目中使用。
npm 安装 ECharts
在 3.1.1 版本之前 ECharts 在 npm 上的 package 是非官方维护的,从 3.1.1 开始由官方 EFE 维护 npm 上 ECharts 和 zrender 的 package。
你可以使用如下命令通过 npm 安装 ECharts
npm install echarts --save
引入 ECharts
通过 npm 上安装的 ECharts 和 zrender 会放在node_modules目录下。可以直接在项目代码中 require('echarts') 得到 ECharts。
var echarts = require('echarts');
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 绘制图表
myChart.setOption({
title: { text: 'ECharts 入门示例' },
tooltip: {},
xAxis: {
data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]
},
yAxis: {},
series: [{
name: '销量',
type: 'bar',
data: [5, 20, 36, 10, 10, 20]
}]
});
按需引入 ECharts 图表和组件
默认使用 require('echarts') 得到的是已经加载了所有图表和组件的 ECharts 包,因此体积会比较大,如果在项目中对体积要求比较苛刻,也可以只按需引入需要的模块。
例如上面示例代码中只用到了柱状图,提示框和标题组件,因此在引入的时候也只需要引入这些模块,可以有效的将打包后的体积从 400 多 KB 减小到 170 多 KB。
// 引入 ECharts 主模块
var echarts = require('echarts/lib/echarts');
// 引入柱状图
require('echarts/lib/chart/bar');
// 引入提示框和标题组件
require('echarts/lib/component/tooltip');
require('echarts/lib/component/title');
// 基于准备好的dom,初始化echarts实例
var myChart = echarts.init(document.getElementById('main'));
// 绘制图表
myChart.setOption({
title: { text: 'ECharts 入门示例' },
tooltip: {},
xAxis: {
data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]
},
yAxis: {},
series: [{
name: '销量',
type: 'bar',
data: [5, 20, 36, 10, 10, 20]
}]
});
对于另一个流行的模块打包工具 browserify 也是同样的用法,这里就不赘述了。
绘制南丁格尔图
饼图主要是通过扇形的弧度表现不同类目的数据在总和中的占比,它的数据格式比柱状图更简单,只有一维的数值,不需要给类目。因为不在直角坐标系上,所以也不需要xAxis,yAxis。
myChart.setOption({
series : [
{
name: '访问来源',
type: 'pie',
radius: '55%',
data:[
{value:400, name:'搜索引擎'},
{value:335, name:'直接访问'},
{value:310, name:'邮件营销'},
{value:274, name:'联盟广告'},
{value:235, name:'视频广告'}
]
}
]
})
异步数据加载和更新
异步加载
入门示例中的数据是在初始化后setOption中直接填入的,但是很多时候可能数据需要异步加载后再填入。ECharts 中实现异步数据的更新非常简单,在图表初始化后不管任何时候只要通过 jQuery 等工具异步获取数据后通过 setOption 填入数据和配置项就行。
var myChart = echarts.init(document.getElementById('main'));
$.get('data.json').done(function (data) {
myChart.setOption({
title: {
text: '异步数据加载示例'
},
tooltip: {},
legend: {
data:['销量']
},
xAxis: {
data: ["衬衫","羊毛衫","雪纺衫","裤子","高跟鞋","袜子"]
},
yAxis: {},
series: [{
name: '销量',
type: 'bar',
data: [5, 20, 36, 10, 10, 20]
}]
});
});
var myChart = echarts.init(document.getElementById('main'));
// 显示标题,图例和空的坐标轴
myChart.setOption({
title: {
text: '异步数据加载示例'
},
tooltip: {},
legend: {
data:['销量']
},
xAxis: {
data: []
},
yAxis: {},
series: [{
name: '销量',
type: 'bar',
data: []
}]
});
// 异步加载数据
$.get('data.json').done(function (data) {
// 填入数据
myChart.setOption({
xAxis: {
data: data.categories
},
series: [{
// 根据名字对应到相应的系列
name: '销量',
data: data.data
}]
});
});
ECharts 中在更新数据的时候需要通过name属性对应到相应的系列,上面示例中如果name不存在也可以根据系列的顺序正常更新,但是更多时候推荐更新数据的时候加上系列的name数据。
loading 动画
如果数据加载时间较长,一个空的坐标轴放在画布上也会让用户觉得是不是产生 bug 了,因此需要一个 loading 的动画来提示用户数据正在加载。
ECharts 默认有提供了一个简单的加载动画。只需要调用 showLoading 方法显示。数据加载完成后再调用 hideLoading 方法隐藏加载动画。
myChart.showLoading();
$.get('data.json').done(function (data) {
myChart.hideLoading();
myChart.setOption(...);
});
移动端自适应
ECharts 工作在用户指定高宽的 DOM 节点(容器)中。ECharts 的『组件』和『系列』都在这个 DOM 节点中,每个节点都可以由用户指定位置。图表库内部并不适宜实现 DOM 文档流布局,因此采用类似绝对布局的简单容易理解的布局方式。但是有时候容器尺寸极端时,这种方式并不能自动避免组件重叠的情况,尤其在移动端小屏的情况下。
另外,有时会出现一个图表需要同时在PC、移动端上展现的场景。这需要 ECharts 内部组件随着容器尺寸变化而变化的能力。
为了解决这个问题,ECharts 完善了组件的定位设置,并且实现了类似 CSS Media Query 的自适应能力。
ECharts组件的定位和布局
大部分『组件』和『系列』会遵循两种定位方式:
left/right/top/bottom/width/height 定位方式:
这六个量中,每个量都可以是『绝对值』或者『百分比』或者『位置描述』。
-
绝对值
单位是浏览器像素(px),用
number形式书写(不写单位)。例如{left: 23, height: 400}。 -
百分比
表示占 DOM 容器高宽的百分之多少,用
string形式书写。例如{right: '30%', bottom: '40%'}。 -
位置描述
- 可以设置
left: 'center',表示水平居中。 - 可以设置
top: 'middle',表示垂直居中。
- 可以设置
这六个量的概念,和 CSS 中六个量的概念类似:
- left:距离 DOM 容器左边界的距离。
- right:距离 DOM 容器右边界的距离。
- top:距离 DOM 容器上边界的距离。
- bottom:距离 DOM 容器下边界的距离。
- width:宽度。
- height:高度。
在横向,left、right、width 三个量中,只需两个量有值即可,因为任两个量可以决定组件的位置和大小,例如 left 和right 或者 right 和 width 都可以决定组件的位置和大小。 纵向,top、bottom、height 三个量,和横向类同不赘述。
center / radius 定位方式:
-
center是一个数组,表示
[x, y],其中,x、y可以是『绝对值』或者『百分比』,含义和前述相同。 -
radius是一个数组,表示
[内半径, 外半径],其中,内外半径可以是『绝对值』或者『百分比』,含义和前述相同。在自适应容器大小时,百分比设置是很有用的。
横向(horizontal)和纵向(vertical)
ECharts的『外观狭长』型的组件(如 legend、visualMap、dataZoom、timeline等),大多提供了『横向布局』『纵向布局』的选择。例如,在细长的移动端屏幕上,可能适合使用『纵向布局』;在PC宽屏上,可能适合使用『横向布局』。
横纵向布局的设置,一般在『组件』或者『系列』的 orient 或者 layout 配置项上,设置为 'horizontal' 或者'vertical'。
于 ECharts2 的兼容:
ECharts2 中的 x/x2/y/y2 的命名方式仍被兼容,对应于 left/right/top/bottom。但是建议写 left/right/top/bottom。
位置描述中,为兼容 ECharts2,可以支持一些看起来略奇怪的设置:left: 'right'、left: 'left'、top: 'bottom'、top: 'top'。这些语句分别等效于:right: 0、left: 0、bottom: 0、top: 0,写成后者就不奇怪了。
Media Query
Media Query 提供了『随着容器尺寸改变而改变』的能力。
如下例子,可尝试拖动右下角的圆点,随着尺寸变化,legend 和 系列会自动改变布局位置和方式。
要在 option 中设置 Media Query 须遵循如下格式:
option = {
baseOption: { // 这里是基本的『原子option』。
title: {...},
legend: {...},
series: [{...}, {...}, ...],
...
},
media: [ // 这里定义了 media query 的逐条规则。
{
query: {...}, // 这里写规则。
option: { // 这里写此规则满足下的option。
legend: {...},
...
}
},
{
query: {...}, // 第二个规则。
option: { // 第二个规则对应的option。
legend: {...},
...
}
},
{ // 这条里没有写规则,表示『默认』,
option: { // 即所有规则都不满足时,采纳这个option。
legend: {...},
...
}
}
]
};
上面的例子中,baseOption、以及 media 每个 option 都是『原子 option』,即普通的含有各组件、系列定义的 option。而由『原子option』组合成的整个 option,我们称为『复合 option』。baseOption 是必然被使用的,此外,满足了某个 query条件时,对应的 option 会被使用 chart.mergeOption() 来 merge 进去。
query:
每个 query 类似于这样:
{
minWidth: 200,
maxHeight: 300,
minAspectRatio: 1.3
}
现在支持三个属性:width、height、aspectRatio(长宽比)。每个属性都可以加上 min 或 max 前缀。比如,minWidth: 200 表示『大于等于200px宽度』。两个属性一起写表示『并且』,比如:{minWidth: 200, maxHeight: 300} 表示『大于等于200px宽度,并且小于等于300px高度』。
option:
media中的 option 既然是『原子 option』,理论上可以写任何 option 的配置项。但是一般我们只写跟布局定位相关的,例如截取上面例子中的一部分 query option:
media: [
...,
{
query: {
maxAspectRatio: 1 // 当长宽比小于1时。
},
option: {
legend: { // legend 放在底部中间。
right: 'center',
bottom: 0,
orient: 'horizontal' // legend 横向布局。
},
series: [ // 两个饼图左右布局。
{
radius: [20, '50%'],
center: ['50%', '30%']
},
{
radius: [30, '50%'],
center: ['50%', '70%']
}
]
}
},
{
query: {
maxWidth: 500 // 当容器宽度小于 500 时。
},
option: {
legend: {
right: 10, // legend 放置在右侧中间。
top: '15%',
orient: 'vertical' // 纵向布局。
},
series: [ // 两个饼图上下布局。
{
radius: [20, '50%'],
center: ['50%', '30%']
},
{
radius: [30, '50%'],
center: ['50%', '75%']
}
]
}
},
...
]
多个 query 被满足时的优先级:
注意,可以有多个 query 同时被满足,会都被 mergeOption,定义在后的后被 merge(即优先级更高)。
默认 query:
如果 media 中有某项不写 query,则表示『默认值』,即所有规则都不满足时,采纳这个option。
容器大小实时变化时的注意事项:
在不少情况下,并不需要容器DOM节点任意随着拖拽变化大小,而是只是根据不同终端设置几个典型尺寸。
但是如果容器DOM节点需要能任意随着拖拽变化大小,那么目前使用时需要注意这件事:某个配置项,如果在某一个 query option 中出现,那么在其他 query option 中也必须出现,否则不能够回归到原来的状态。(left/right/top/bottom/width/height 不受这个限制。)
『复合 option』 中的 media 不支持 merge
也就是说,当第二(或三、四、五 …)次 chart.setOption(rawOption) 时,如果 rawOption 是 复合option(即包含 media列表),那么新的 rawOption.media 列表不会和老的 media 列表进行 merge,而是简单替代。当然,rawOption.baseOption仍然会正常和老的 option 进行merge。
其实,很少有场景需要使用『复合 option』来多次 setOption,而我们推荐的做法是,使用 mediaQuery 时,第一次setOption使用『复合 option』,后面 setOption 时仅使用 『原子 option』,也就是仅仅用 setOption 来改变 baseOption。
Tableau 是能够帮助大家查看并理解数据的商业智能软件。 Icon ideas 快速分析 在数分钟内完成数据连接和可视化。Tableau 比现有的其他解决方案快 10 到 100 倍。 Icon people简单易用 任何人都可以使用直观明了的拖放产品分析数据。无需编程即可深入分析。 Icon any-data-anywhere 大数据,任何数据 无论是电子表格、数据库还是 Hadoop 和云服务,任何数据都可以轻松探索。 Icon tableau-desktop (场景桌面)智能仪表板 集合多个数据视图,进行更丰富的深入分析。数据可视化最佳做法等待您去体验。 Icon access-big-data 自动更新 通过实时连接获取最新数据,或者根据制定的日程表获取自动更新。 Icon access-big-data(图标访问大数据) 瞬时共享 只需数次点击,即可发布仪表板,在网络和移动设备上实现实时共享。
5个交互式图
5个用于创建交互式图的Python库
梅利莎比耶利
内容营销
根据数据可视化专家Andy Kirk的说法,有两种类型的数据可视化:探索性和解释性。解释性可视化的目的是讲述故事 - 它们是经过精心构建的,用于表达关键发现。
另一方面,探索性可视化“创建数据集或主题的界面……它们促进用户探索数据,让他们发掘自己的见解:他们认为相关或有趣的发现。”
通常,探索性可视化是互动的。虽然有许多Python绘图库,但只有少数人可以创建可以在线嵌入和分发的交互式图表。今天我们分享了五个我们的最爱。
请在评论中告诉我们您喜欢使用哪些图书馆。我们使用客户请求来确定库的优先级,以支持模式Python笔记本。
mpld3
自定义插件示例(Jake Vanderplas)
mpld3汇集了Python的核心绘图库matplotlib和流行的JavaScript图表库D3,以创建浏览器友好的可视化。您可以在matplotlib中创建一个绘图,使用兼容Python和JavaScript的插件添加交互式功能,然后使用D3渲染它。
mpld3包含用于缩放,平移和添加工具提示的内置插件(当您将鼠标悬停在数据点上时显示的信息)。然而,mpld3的真正强大之处在于其文档齐全的API,它允许您创建自定义插件。如果您熟悉D3和JavaScript,那么您可以创建的图表无止境。
当您的绘图准备好发布时,在末尾添加一行额外的代码,将您的绘图转换为HTML和JavaScript字符串,可以嵌入到任何网页中。
mpld3最适合中小型数据集; 具有数千个数据点的图表在浏览器中将变得迟缓。
创建人: Jake Vanderplas 哪里可以了解更多信息: http ://mpld3.github.io/
pygal

基本点图(Florian Mounier)
pygal是一个很好的选择,用很少的代码行生成漂亮的开箱即用的图表。每种图表类型都打包成一个方法(例如, pygal.Histogram()制作直方图,pygal.Box()制作一个箱形图),并且有各种各样的彩色默认样式。如果您想要更多控制,您可以配置绘图的几乎每个元素 - 包括大小调整,标题,标签和渲染。
图表默认显示工具提示,但目前无法放大或缩小图表。
您可以将图表输出为SVG,并将其添加到带有嵌入标记的网页中,或者将代码直接插入HTML中。与mpld3一样,pygal适用于较小的数据集。
创建人: Florian Mounier 在哪里可以了解更多信息: http ://www.pygal.org/en/latest/index.html
背景虚化
交叉过滤器示例(Continuum Analytics)
Bokeh的灵感来自于The Grammar of Graphics中概述的概念。您可以将组件层叠在一起以创建完成的绘图 - 例如,您可以从轴开始,然后添加点,线,标签等。
绘图可以作为JSON对象,HTML文档或交互式Web应用程序输出。Bokeh很好地允许用户在浏览器中操作数据,使用滑块和下拉菜单进行过滤。与mpld3类似,您可以缩放和平移以导航绘图,但您也可以使用框或套索选择专注于一组数据点。
创建者: Continuum Analytics 哪里可以了解更多信息: http ://bokeh.pydata.org/en/latest/
HoloViews
使用Bokeh后端(IOAM)映射
HoloViews实际上并不是一个绘图库。相反,它允许您构建有助于可视化的数据结构。将数据移动到HoloView Container对象(例如用于多变量分析的GridMatrix或用于显示彼此相邻的组件的布局)之后,您可以直观地浏览数据。绘图分别在matplotlib或Bokeh后端上进行,因此您可以专注于数据,而不是编写绘图代码。
HoloViews提供的主要交互功能是滑块,因此人们可以使用变量来查看其效果。使用Bokeh后端时,您可以将滑块组件与Bokeh的工具结合使用,以便探索绘图,例如缩放和平移。
HoloViews与Seaborn和pandas集成,开启了pandas DataFrames和Seaborn统计图表的强大功能。
创建者: Jean-Luc Stevens,Philipp Rudiger和James A. Bednar 在哪里可以了解更多信息: http ://holoviews.org/
Plotly
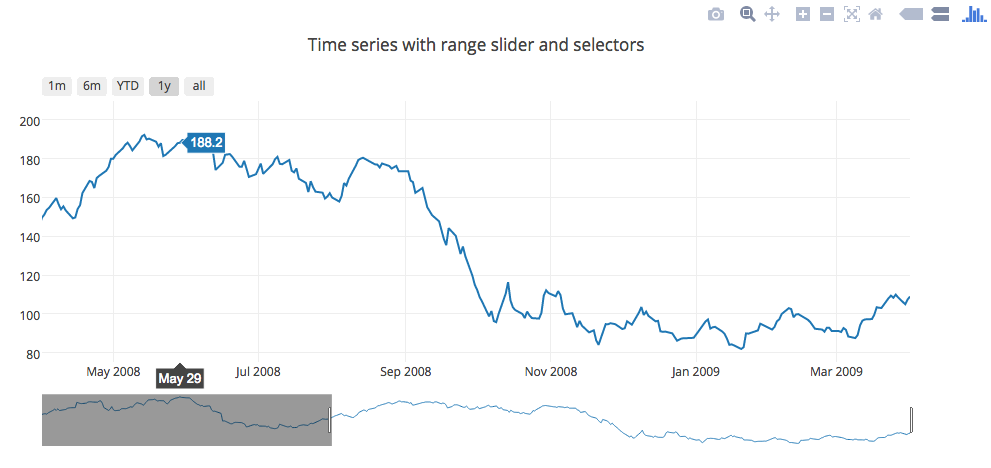
范围滑块示例(Plotly)
从简陋的条形图到错综复杂的3D网络图,Plotly拥有广泛的出版品质图表类型。
默认情况下,Plotly是基于Web的服务,但您可以在Python中脱机使用库并将图上传到Plotly的免费公共服务器或付费私有服务器。从那里,您可以将您的图表嵌入到网页中。
所有Plotly图表都包含工具提示,一旦使用Plotly的JavaScript API嵌入,您就可以在图表顶部构建自定义控件(如滑块和滤镜)。
另一种在Plotly中工作并共享绘图的方法是在Mode中。您可以使用SQL提取数据,使用Python Notebook中的Plotly离线库来绘制查询结果,然后将交互式图表添加到报表中。该报告以可共享的URL在线生存,并且可以嵌入到其他页面中,如此图表显示自1950年以来Lego集的大小如何变化:
创建者: Plotly,可在模式 中获取更多信息: https ://plot.ly/python/
在模式中尝试Plotly。
没有编码经验?没问题。 使用我们的免费教程,使用真实数据学习Python。
topN
在系统中,我们经常会遇到这样的需求:将大量(比如几十万、甚至上百万)的对象进行排序,然后只需要取出最Top的前N名作为排行榜的数据,这即是一个TopN算法。常见的解决方案有三种:
(1)直接使用List的Sort方法进行处理。
(2)使用排序二叉树进行排序,然后取出前N名。
(3)使用最大堆排序,然后取出前N名。
第一种方案的性能是最差的,后两种方案性能会好一些,但是还是不能满足我们的需求。最主要的原因在于使用二叉树和最大堆排序时,都是对所有的对象进行排序,而不是将代价花费在我们需要的少数的TopN上。对于堆结构来说,并不需要你获取所有的数据,只需要对前N个数据进行处理。因此可以通过堆栈的进入排出,用小顶堆实现,调整最小堆的时间复杂度为lnN,总时间复杂度为nlnN
myheap:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# 最小堆化heap
def siftdown(heap, start, end):
while True:
left_child = start * 2 + 1
if left_child > end:
break
if left_child + 1 <= end:
if heap[left_child] > heap[left_child+1]:
left_child += 1
if heap[left_child] < heap[start]:
heap[left_child], heap[start] = heap[start], heap[left_child]
start = left_child
else:
break
def minheapstyle(heap):
first = len(heap) // 2 - 1
for x in xrange(first, -1, -1):
siftdown(heap, x, len(heap)-1)
def push(heap, item):
heap.append(item)
minheapstyle(heap)
def pushpop(heap, item):
if heap[0] < item:
heap[0] = item
minheapstyle(heap)
if __name__ == '__main__':
heap = [10,4,5,3,5,6,2]
minheapstyle(heap)
print heap
TOPN:
import myheap
def findminn(list, n):
heap = []
for x in list:
if len(heap) < n:
myheap.push(heap, x)
else :
myheap.pushpop(heap, x)
return heap
if __name__ == '__main__':
l = [5,6,7,8,9,10,5646]
#n=5
heap = findminn(l,5)
print heap
虽然python有类似的最小堆结构,但是当我们需要处理更复杂的问题时,可能依然需要自己定制。
python实现Execl转csv方法收集
1.使用xlrd
# -*- coding: utf-8 -*-
import xlrd
import csv
from os import sys
def csv_from_excel(excel_file):
workbook = xlrd.open_workbook(excel_file)
all_worksheets = workbook.sheet_names()
for worksheet_name in all_worksheets:
worksheet = workbook.sheet_by_name(worksheet_name)
your_csv_file = open(''.join([worksheet_name,'.csv']), 'wb')
wr = csv.writer(your_csv_file, quoting=csv.QUOTE_ALL)
for rownum in xrange(worksheet.nrows):
wr.writerow([unicode(entry).encode("utf-8") for entry in worksheet.row_values(rownum)])
your_csv_file.close()
if __name__ == "__main__":
csv_from_excel(sys.argv[1])
===============================
# -*- coding: utf-8 -*-
import xlrd
import xlwt
import sys
from datetime import date,datetime
def read_excel(filename):
workbook = xlrd.open_workbook(filename)
# print sheet2.name,sheet2.nrows,sheet2.ncols
sheet2 = workbook.sheet_by_index(0)
for row in xrange(0, sheet2.nrows):
rows = sheet2.row_values(row)
def _tostr(cell):
if type(u'') == type(cell):
return "\"%s\"" % cell.encode('utf8')
else:
return "\"%s\"" % str(cell)
print ','.join([_tostr(cell) for cell in rows ])
if __name__ == '__main__':
filename = sys.argv[1]
read_excel(filename)
===============================
2. 使用pandas
import pandas as pd
data_xls = pd.read_excel('your_workbook.xls', 'Sheet1', index_col=None)
data_xls.to_csv('your_csv.csv', encoding='utf-8')
安装pandas,看实际情况使用:
安装numpy:
pip install numpy
安装pandas:
https://pypi.python.org/pypi/pandas
安装过程遇到报错找不到Python:http://blog.csdn.net/zdnlp/article/details/12171687
安装dateutil:
https://pypi.python.org/pypi/python-dateutil
测试:
import pandas
3. csvkit
推荐算法思路
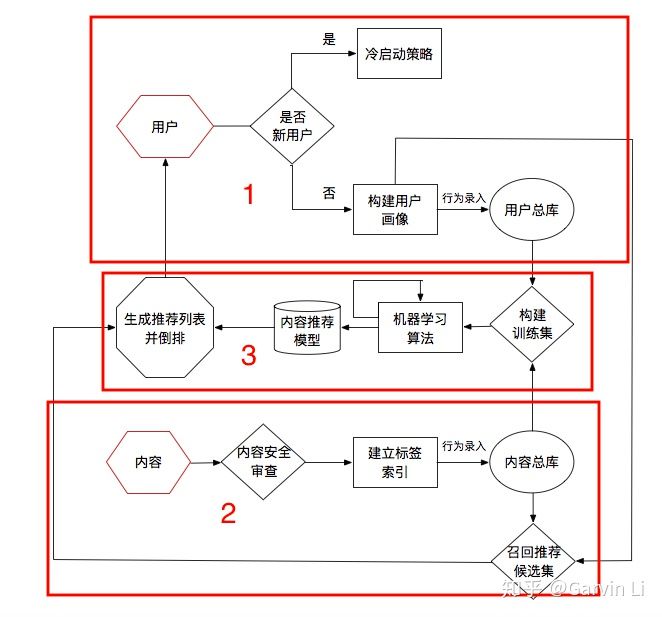



协同过滤
协同过滤
collaborative filtering
matrix factorization
[数] 矩阵因子分解
logistic regression
逻辑回归;罗吉斯回归
maximum(极大的) entropy model最大熵模型
DNN
深度神经网络(Deep Neural Networks);有线电视机新闻网(Dable News Network)
feature engineering 特征工程
GBDT(梯度提升决策树)是为了解决一般损失函数的优化问题,方法是用损失函数的负梯度在当前模型的值来模拟回归问题中残差的近似值。
SVD(奇异值分解) SVD (singular value decomposition)
矩阵因子分解
逻辑回归
属于对数线性模型 - 归一化。sklearn
最大熵模型属于对数模型
特征工程
深度神经网络
梯度提升决策树
是为了解决一般损失函数的优化问题,方法是用损失函数的负梯度在当前模型的值来模拟回归问题中残差的近似值。
奇异值分解
优点:简化数据,去除噪声点,提高算法的结果; 缺点:数据的转换可能难以理解; 适用于数据类型:数值型。
=
选择奇异值中占总奇异值总值90%的那些奇异值。
#在Numpy中有一个称为线性代数linalg的线性代数工具箱
from numpy import *
from numpy import linalg as la
df = mat(array([[1,1],[1,7]]))
U,Sigma,VT = la.svd(df)
print(U)
# [[ 0.16018224 0.98708746]
# [ 0.98708746 -0.16018224]]
print(Sigma)
# [7.16227766 0.83772234]
print(VT)
# [[ 0.16018224 0.98708746]
# [ 0.98708746 -0.16018224]]
推荐系统的评判标准 用户满意度 描述用户对推荐结果的满意程度,这是推荐系统最重要的指标。
一般通过对用户进行问卷或者监测用户线上行为数据获得。
预测准确度 描述推荐系统预测用户行为的能力。一般通过离线数据集上算法给出的推荐列表和用户行为的重合率来计算。重合率越大则准确率越高。
覆盖率 描述推荐系统对物品长尾的发掘能力。一般通过所有推荐物品占总物品的比例和所有物品被推荐的概率分布来计算。比例越大,概率分布越均匀则覆盖率越大。
多样性 描述推荐系统中推荐结果能否覆盖用户不同的兴趣领域。一般通过推荐列表中物品两两之间不相似性来计算,物品之间越不相似则多样性越好。
新颖性 如果用户没有听说过推荐列表中的大部分物品,则说明该推荐系统的新颖性较好。可以通过推荐结果的平均流行度和对用户进行问卷来获得。
惊喜度 如果推荐结果和用户的历史兴趣不相似,但让用户很满意,则可以说这是一个让用户惊喜的推荐。可以定性地通过推荐结果与用户历史兴趣的相似度和用户满意度来衡量。
简而言之,一个好的推荐系统就是在推荐准确的基础上,给所有用户推荐的物品尽量广泛(挖掘长尾),给单个用户推荐的物品尽量覆盖多个类别,同时不要给用户推荐太多热门物品,最牛逼的则是能让用户看到推荐后有种「相见恨晚」的感觉。
参考文献
echarts的使用散点图说明
https://blog.csdn.net/tao_wei162/article/details/84816212
ECharts
https://www.cnblogs.com/huqinhan/p/5776451.html
Pandas分析Nginx日志求pv, uv
pv页面浏览量(页—景色);uv唯一的访客
https://www.jianshu.com/p/a04639f9a63c
highcharts
https://www.runoob.com/highcharts/highcharts-tutorial.html
tableau
https://www.tableau.com/zh-cn/trial/tableau-software
5个交互式图
https://mode.com/blog/python-interactive-plot-libraries/
pandas手册
https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.plot.bar.html
推荐系统中的推荐理由实现,有什么好的思路吗?
https://www.zhihu.com/question/19576347
xgboost
kaggle比赛实例:房价预测之xgboost调参
https://zhuanlan.zhihu.com/p/30565202
2019腾讯广告算法大赛方案分享(冠军)
https://zhuanlan.zhihu.com/p/73062485
2019腾讯广告算法大赛-冠军之路
https://mp.weixin.qq.com/s/nBEd9ykNYssXgOBkh-GawA
一文梳理2019年腾讯广告算法大赛冠军方案
https://mp.weixin.qq.com/s/8E8XwQgcULF3sdDrHj1HpQ
数与码
https://zhuanlan.zhihu.com/shuma
风控
面试阿里数据分析风控岗挂掉的经历&反思
https://zhuanlan.zhihu.com/p/46866128




