
Java机器学习库
机器学习的标准范式表达
对于一个Task及其Performance的度量方法,给出特定的Algorithm,能够通过利用Experience Data不断提高在该Task上的Performance的方法,就称为机器学习。
其实这个定义就是“学习”的全部含义,这个事情按照机器的思路来做,就是机器学习
只要算法合理,每次学习都能有提高,机器有足够的运算能力,就能将机器的能力达到极致从而超越人类。机器学习的本质就是建立(”数据”——”认知”)关系库。
机器学习说白了跟人类学习是一样的,只不过机器可以无止境的学习,并且,机器学习时完全不需要懂什么原理,只要知道怎么去实现就行。就如Alpha Go,你们觉得它懂得棋理吗?我觉得肯定不懂,但通过对无数的棋谱的学习,让人觉得它肯定掌握了围棋的真谛。
感知机
感知机(perceptron)是二分类的线性分类模型,输入为实例的特征向量,输出为实例的类别(取+1和-1)。感知机对应于输入空间中将实例划分为两类的分离超平面。感知机旨在求出该超平面,为求得超平面导入了基于误分类的损失函数,利用梯度下降法 对损失函数进行最优化(最优化)。感知机的学习算法具有简单而易于实现的优点,分为原始形式和对偶形式。感知机预测是用学习得到的感知机模型对新的实例进行预测的,因此属于判别模型。感知机由Rosenblatt于1957年提出的,是神经网络和支持向量机的基础。
感知机要做的,就是根据各点坐标,将错误的直线纠正为正确的,这样得到的直线就是训练的结果。
/*
* 判断所有点的位置关系,进行分类
*/
public boolean classify() {
boolean flag = false;
while (!flag) {
for (int i = 0; i < arrayList.size(); i++) {
if (Anwser(arrayList.get(i)) <= 0) {
Update(arrayList.get(i));
break;
}
if (i + 1 == arrayList.size()) {
flag = true;
}
}
}
return true;
}
/*
* 点乘返回sum
*/
private double Dot(double[] w, double[] x) {
double sum = 0;
for (int i = 0; i < x.length; i++) {
sum += w[i] * x[i];
}
return sum;
}
/*
* 返回函数计算的值
*/
private double Anwser(Point point) {
System.out.println(Arrays.toString(w));
System.out.println(b);
return point.y * (Dot(w, point.x) + b);
}
public void Update(Point point) {
for (int i = 0; i < w.length; i++) {
w[i] += eta * point.y * point.x[i];
}
b += eta * point.y;
return;
}
结果
1 Point p1 = new Point(new double[] { 0, 0, 0, 1 }, -1);
2 Point p2 = new Point(new double[] { 1, 0, 0, 0 }, 1);
3 Point p3 = new Point(new double[] { 2, 1, 0, 0 }, 1);
4 Point p4 = new Point(new double[] { 2, 1, 0, 1 }, -1);
云标签
离散数学 C语言游戏 经济刑法 神经网络SVM 决策树 javafx 协同进化wxpython PAT web Sci-hub MatlabCSS HTML 计算机组成原理 socketWindows 贪心算法 PyQt JavaScriptwordpress 格雷码 机器学习 googlewin10 PEP8 AUC 数字逻辑 网络原理 朴素贝叶斯 多线程 JAVA TensorFlow 编程语言概述 SEE 动态规划 ROC ideasVNS 特征选择 算法 人工智能 软件工程 Cyber Crime nltk Linux 操作系统原理app 汇编语言 GUI NSGA-II 聚类 k-means KMP算法 数据库 课程设计C++ 正则表达式 深度学习 CSO算法 生命周期模型 tkinter SAA numpy 量化投资Github 多目标优化算法 PythonPSO算法 knn MIC 数据结构 SQL C语言 Android json ACO算法
机器学习及人工智能
机器学习与深度学习可以看作人工智能的内部模型提炼过程,人工智能则是对外部的智能反应。
人工智能 人工智能(Artificial Intelligence),学术定义为用于研究,模拟及扩展人的智能应用科学;AI在计算机领域研究涉及机器人,语言识别,图像识别,自然语言处理等。AI的研究会横跨多门学科,如计算机,数学,生物,语言,声音,视觉甚至心理学和哲学。
其中AI的核心是做到感知,推断,行动及根据经验值进行调整,即类似人类的智慧体智能学习提升。
深度学习
深度学习则泛指深度神经网络学习,如卷积神经网络(Convolutional Neural Nets,CNN),把普通神经网络从3-4层升华到8-10层从而获取更精准模型,其应用如图像视频识别等。
人工智能,神经网络并非什么新鲜事物,早在20-30年前就已经诞生,而深度学习则借助因互联网而诞生的大数据,及近些年发展的强大运算能力(图形处理GPU)而大放光彩,甚至推动引爆了新一代的人工智能。
机器学习
机器学习的学究的定义为“计算机程序如何随着经验积累自动提高性能”,经典英文定义为
“A computer program is said to learn from experience E with respect to some class of tasks T and performance measure P, if its performance at tasks in T, as measured by P, improves with experience E.”,即“对于某类任务T和性能度量P,如果一个计算机程序在T上以P衡量的性能随着经验E而自我完善,那么我们称这个计算机程序在从经验E学习”, 通俗点说既是让机器来模拟人类来学习新的知识与技能,重点是不是通过某精妙算法而达成,而是让程序去通过学习发现提高,举一反三, 正所谓授之以鱼不如授之以渔。

机器学习框架图
蓝色:情景,取决于数据的具体情况,比如在没有数据label的情景下不得不放弃监督学习,选择无监督学习,在建模的过程中应考虑的情景 红色:问题,即机器学习的目的 绿色:算法
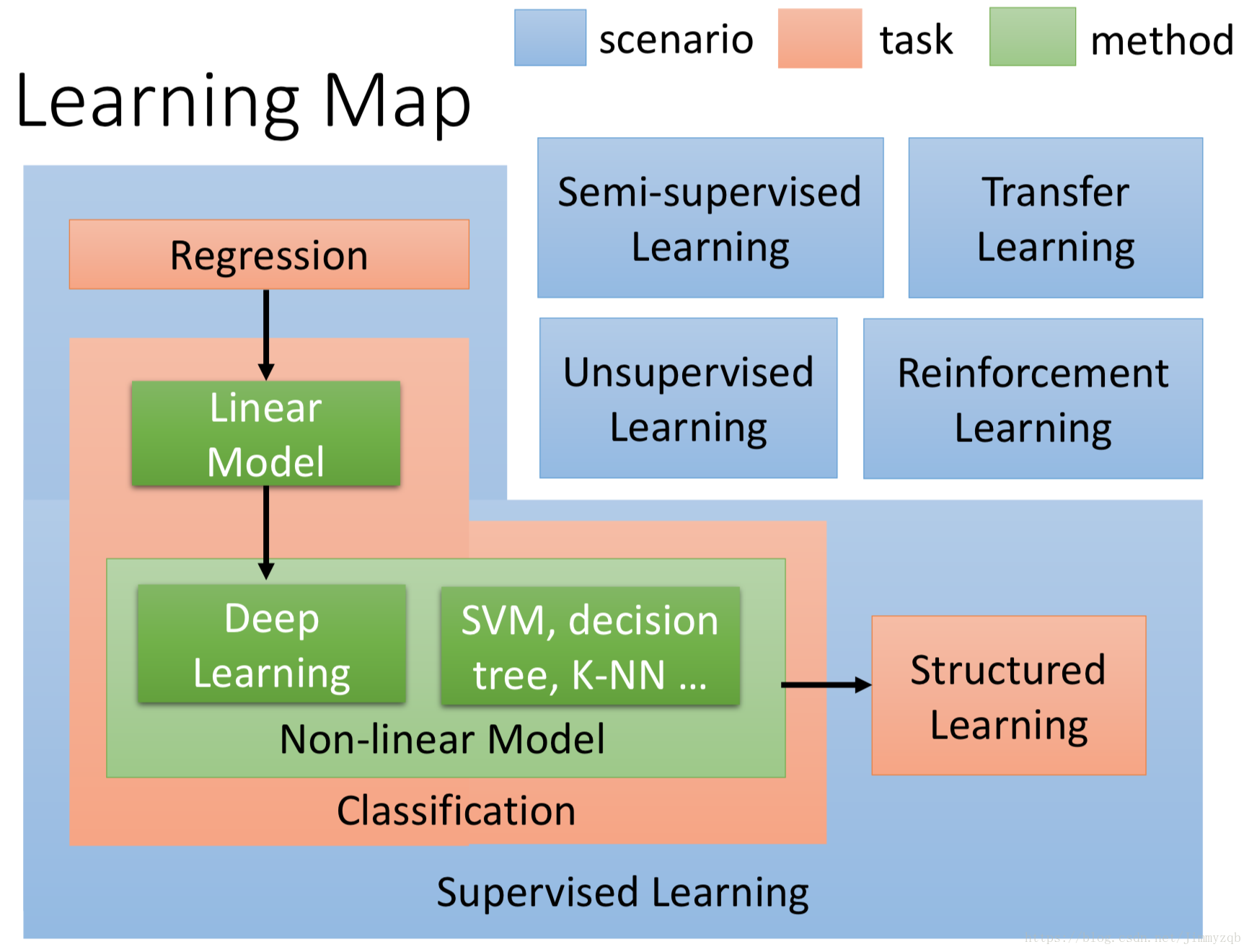

机器学习分类
机器学习在学习的方法广义上分为有监督学习与无监督学习。
有监督学习(Supervised Learning)
监督学习,通常对具有标记分类的训练样本特征进行学习,标记即已经知道其对应正确分类答案;而学习则本质是找到特征与标签(正确答案)之间的关系(函数),从而当训练结束,输入无标签的数据时,可以利用已经找出的关系方法进行分析得出数据标签。
监督学习类似我们在学校的学习,通常的题目都会有“正确答案”,以便于我们每学期学习结束(训练),参加未知的考试作为检验。
监督学习的模型及流程:
获取数据并确定所处理数据类型
确定并提取训练数据集的特征(feature)
选择机器学习方法如向量机或决策树
获取最终机器模型
对机器学习模型进行评估
监督学习方法及用途
常用的监督机器学习方法有如人工神经网络,决策树,传统贝叶斯分类器,支撑向量机(SVM)等。
监督学习的主要用途通常用来进行样本分类与回归(找到最为接近的函数用于预测),而又根据其输出结果连续还是离散分为回归分析(Regression)与分类(Classification)。
无监督学习(Unsupervised Learning)
反之,无监督学习则通常学习数据只有特征向量,没有标签(答案),学习模型通过学习特征向量发现其内部规律与性质,从而把数据分组聚类(Clustering)。
无监督学习更类似我们的真实世界,去探索发现一些规律及分类。
举个例子,如果把监督学习看作未成年时在家长及老师的“监督”下做告知正确的事,则无监督学习就是成年后踏入社会,自己去探索,发现,适应社会了。
无监督学习方法及用途
常用的无监督学习方法有: K-Means, 层次化聚类(Hierarchical Clustering),社交网络分析,一些数据挖掘算法等。
无监督学习的用途则主要用来在未知(无标签)数据中发现相似或者隐藏结构并进行聚类(Clustering),或者发现数据对应输入空间的分布之密度估计等。
当然对于数据样本介于无标记及部分标记之间,这种机器学习则被称为半监督学习(semi-supervised learning),我们暂不介绍。
3线性回归算法
总体来说,机器学习中的回归算法的本质是通过对样本数据的收集,给出假设的函数模型,而此函数包含未知参数,机器学习的过程就是解方程或者找到最优解,当验证通过后,从而可以用该函数去预测测试新数据。
线性回归
回归,统计学术语,表示变量之间的某种数量依存关系,并由此引出回归方程,回归系数。
线性回归(Linear Regression),数理统计中回归分析,用来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,其表达形式为y = w'x+e,e为误差服从均值为0的正态分布,其中只有一个自变量的情况称为简单回归,多个自变量的情况叫多元回归。
机器学习基本概念
1、机器学习算法类型
根据训练数据提供的信息以及反馈方式的不同,可以分为:
* 有监督学习(Supervised Learning):每组训练数据都有一个明确的标签和结果,利用这些已知的数据来学习模型的参数,使得模型预测的目标标签和真实标签尽可能接近。涉及的应用:预测房屋的价格,股票的涨停,垃圾邮件检测。神经网络也是一种监督学习的方式。常见算法有逻辑回归(Logistic Regression)和反向传递神经网络(Back Propagation Neural Network)。根据目标标签的类型不同,又可以分为:
* 回归(Regression)问题:目标标签y是连续值(实数或连续整数),f(x)的输出也是连续值。
* 分类(Classification)问题:目标标签y是离散的类别(符号)。在此问题中,通过学习得到的决策函数也叫分类器。
无监督学习(Unsupervised Learning):学习的数据不包含目标标签,需要学习算法自动学习到一些有价值的信息。一个典型的问题就是聚类,常见算法包括Apriori算法以及k-Means算法。
半监督学习(Semi-supervised Learning):少量有目标标签的样本和大量没有目标标签的样本。先试图对未标识数据进行建模,在此基础上对标识的数据进行预测,如图论推理算法或者拉普拉斯支持向量机等。
强化学习(Reinforcement Learning):输入数据直接反馈到模型,模型必须立刻做出调整。也就是常说的从经验中总结提升。常见的应用场景包括动态系统以及机器人控制等,Google的AlphaGo就是运用了这种学习方式。算法本身会总结失败和成功的经验来达到很高的成功率。常见算法包括Q-Learning以及时间差学习(Temporal difference learning)。
遗传算法(Genetic Algorithm):模拟进化理论,适者生存不适者淘汰,通过淘汰机制选择最优化的模型。
在企业数据应用的场景下, 人们最常用的可能就是监督式学习和非监督式学习的模型。 在图像识别等领域,由于存在大量的非标识的数据和少量的可标识数据, 目前半监督式学习是一个很热的话题。 而强化学习更多的应用在机器人控制及其他需要进行系统控制的领域。
2、风险函数与损失函数
我们需要建立一些准则来衡量决策函数的好坏,一般是定义一个损失函数L(y,f(x,θ)),然后在所有的训练样本上来评价决策函数的风险。
损失函数
给定一个实例(x,y),真实目标是y,机器学习模型预测的结果为f(x,θ),损失函数就是用来估量模型的预测值和真实值的不一致程度,它是一个非负实值函数,损失函数越小,模型的鲁棒性就越好。损失函数是经验风险函数的核心部分,也是结构风险函数的重要组成部分。
常见的损失函数有如下几类:
* 0-1损失函数:0-1损失函数(0-1 loss function)是
L(y,f(x,θ))=={01if y=f(x,θ)if y≠f(x,θ)I(y≠f(x,θ))
* 平方损失函数:通常为线性回归的损失函数。
L(y,y^)=(y−f(x,θ))2
最小二乘法和梯度下降法都是通过求导来求损失函数的最小值。
* 最小二乘法:直接对L(y,f(x,θ))求导找出全局最小,是非迭代法;
* 梯度下降法:迭代法,先给定一个,然后向下降最快的方向调整,在若干次迭代之后找到局部最小。其缺点是到最小点的时候收敛速度变慢,并且对初始点的选择极为敏感。
* 交叉熵损失函数:对于分类问题,预测目标为y为离散的类别,模型输出f(x,θ)为每个类的条件概率。
假设y∈{1,...,C},模型预测的第i个类的条件概率P(y=i∣x)=fi(x,θ),则f(x,θ)满足
fi(x,θ)∈[0,1],∑i=1Cfi(x,θ)=1
f_y(x,\theta)可以看做真实类别y的似然函数。参数可以用最大似然估计来优化。考虑到计算问题,我们经常使用最小化负对数似然,也就是负对数似然损失函数。
L(y,f(x,θ))=−logfy(x,θ)
如果我们用one-hot向量y来表示目标类别c,其中只有yc=1,其余的向量元素都为0.
负对数似然函数可以写为:
L(y,f(x,θ))=−∑i=1Cyilogfi(x,θ)
yi也可以看成是真实类别的分布,这样上面的公式恰好是交叉熵的形式,因此,负对数似然函数也常叫做交叉熵损失函数。
* Hinge损失函数:对于两类分类问题,假设y和f(x,θ)的取值为{−1,+1}。Hinge损失函数的定义如下:
L(y,f(x,θ))=max(0,1−yf(x,θ))=|1−yf(x,θ)|+.
风险函数
经验风险:Remp(θ),在已知的训练样本(经验数据)上计算得来。用对参数θ求经验风险来逐渐逼近理想的期望风险的最小值,这一原则我们称为经验风险最小化原则。
结构风险:Rstruct(θ),在经验风险最小化的原则上加上参数的正则化,叫做结构风险最小化原则。
3、常见的基本概念
数据
所有能由计算机程序处理的对象的总称,可以是数字、字母和符号等。
特征
在现实世界中,原始数据通常并不都是以连续变量或离散变量的形式存在的,我们首先需要抽取出一些可以表征这些数据的数值型特征,这些数值型特征可以表示为向量形式,也称为特征向量。
参数与超参数
需要通过学习算法学习得来的就是参数。超参数是参数的参数。
特征学习
如何自动地学习有效的特征也成为机器学习中一个重要的研究内容,也就是特征学习,也叫表示学习。特征学习分成两种,一种是特征选择,是在很多特征集合选取有效的子集;另一种是特征提取,是构造一个新的特征空间,并将原始特征投影到新的空间中。
样本
按照一定的抽样规则从从全部数据中取出的一部分数据,是实际观测到的数据。
训练集和测试集
一组样本的集合就称为数据集。为了检验机器学习算法的好坏,一般将数据集分成两部分:训练集和测试集。训练集用来进行模型学习,测试集用来进行模型验证。
正例和负例
对于两类分类问题,常用正例和负例来分别表示属于不同类别的样本。
判别函数
经过特征提取后,一个样本可以表示为k维特征空间中的一个点。为了对这些点进行分类,需要一些超平面来将这个特征空间分成一些互不重叠的子区域,使得不同类别的点分布在不同的子区域中,这些超平面就是判别界面。
为了定义这些超平面,就需要引入判别函数。假设变量z∈Rm为特征空间中的点,这个超平面由所有满足函数f(z)=0的点组成。这里的的f(z)就是判别函数。
java内容
(1)Java语言的概述和基础(杂、记)
Java语言的概述、开发环境的搭建、变量和注释、数据类型和运算符、流程控制语句、数组以及应用等
用时5天左右
编写猜数字游戏和双色球抽奖游戏
(2)Java语言中面向对象编程(难点、理解)
类和对象、封装、继承、多态、抽象类、接口以及内部类等
用时5天左右
编写五子棋游戏和扫雷游戏
(3)Java语言的核心类库(用)
Object类、String类、集合类、异常、IO流、多线程和网络编程、反射、设计和算法等
用时12天左右
编写学生信息管理系统和简易聊天室
学习时间
上午:
8:30 ~ 8:45 每日一测
8:45 ~ 9:45 第一节
10:00 ~ 11:00 第二节
11:15 ~ 12:15 第三节
下午:
14:00 ~ 15:00 第一节
15:15 ~ 16:15 第二节
16:30 ~ 17:30 第三节和答疑
晚上:
18:30 ~ 22:50 自习
-——————————————————————————————————-
applewebdata://64CE9B6E-98D7-4B4E-AD87-DB344128C588/day01/day01.txt
day01
1.计算机的体系结构(常识)
1.1基本概念
1.2常见的硬件
1.3常见的软件
1.4计算机的体系结构
2.Java语言的概述(常识)
2.1 Java语言的背景
2.2 Java的主要版本
3.开发环境的搭建(重点)
3.1 jdk的下载和安装
3.2相关的概念(记住)
3.3编写Java程序的流程
3.4常用的快捷键
3.5环境变量的配置
3.6跨平台原理
day02
1.变量和注释(重点)
1.1变量的基本概念
1.2变量的声明方式
1.3标识符(变量名)的命名规则(笔试题)
1.4注释
2.数据类型
2.1基本分类
2.2常见的进制
2.3进制之间的转换(尽量掌握)
2.4单个字节表示的整数范围(重中之重)
2.5整数类型
2.6浮点类型
day03
1.数据类型
1.1布尔类型
1.2字符类型
1.3基本数据类型之间的转换
2.运算符(重点)
2.1算术运算符
2.2关系/比较运算符
2.3逻辑运算符
2.4自增减运算符
2.5条件/三目运算符
2.6赋值运算符
2.7移位运算符(了解)
2.8位运算符(了解)
2.9运算符的优先级
day04
1.分支结构(重中之重)
1.1基本概念
1.2 if分支结构
1.3 if-else分支结构
1.4 if-else if-else分支结构
1.5 switch-case分支结构(会用即可)
2.循环结构(重中之重、难点)
2.1基本概念
2.2 for循环
2.3 break和continue关键字
2.4特殊的循环
day05
1.循环结构
1.1 for循环(重中之重)
1.2双重for循环(重中之重、难点)
1.3 while循环(会用即可)
1.4 do-while循环(会用即可)
2.一维数组(重点)
2.1基本概念
2.2数组的声明
day06
1.二维数组(会用即可)
1.1基本概念
1.2声明方式
2.面向对象编程的概念(理解)
2.1什么是对象?
2.2什么是面向对象?
2.3什么是面向对象编程?
2.4如何学好面向对象编程?
2.5为什么需要面向对象编程?
3.类和对象以及引用(重中之重、概念多)
3.1基本概念
3.2类的定义
3.3对象的创建
3.4引用
4.成员方法(重中之重)
4.1语法格式
4.2成员方法的详解
4.3方法的调用
day07
1.构造方法和方法重载
1.1 构造方法(重中之重)
1.2 方法的重载(Overload 会用即可笔试题)
2.this关键字(原理、理解)
2.1 基本概念
2.2 使用场合
3.方法的传参和递归调用
3.1 方法的传参过程(原理、尽量理解)
3.2 递归调用(难点、重点)
day08
1.封装(重中之重20遍)
1.1 基本概念
1.2 封装的流程
2.static关键字(重点)
2.1 基本概念
2.2 使用方式
2.3 构造块和静态代码块(了解)
2.4 单例设计模式(重中之重 20遍)
3.继承(重中之重)
3.1 基本概念
3.2 注意事项
day09
1.继承(重中之重)
1.1 基本概念
1.2 注意事项
1.3 this和super的比较(了解)
1.4 方法的重写(Override)
2.访问控制(笔试题)
2.1 常见的访问控制符
2.2 包的定义
3.final关键字(重点)
3.1 基本概念
3.2 使用方式
4.对象创建的过程(了解)
4.1 单个对象创建的执行过程
4.2 子类对象创建的执行过程
5.多态(重中之重、难点)
5.1 基本概念
5.2 语法格式
5.3 多态的效果
5.4 引用数据类型之间的转换
5.5 实际意义
day10
1.抽象类(重点)
1.1 抽象方法的概念
1.2 抽象类的概念
1.3 注意事项
1.4 实际意义
2.接口(重点)
2.1 基本概念
2.2 类和接口之间的比较
2.3 抽象类和接口之间的区别(笔试题)
3.内部类(了解)
3.1 基本概念
3.2 语法格式
3.3 基本作用
3.4 基本分类
3.5 匿名内部类(重点、难点)
day11
1.Object类
1.1 常用的包
1.2 Object类
2.包装类和数学处理类
2.1 包装类(理解)
2.2 Integer类(会用即可)
2.3 BigDecimal类(查手册会用即可)
2.4 BigInteger类(查手册会用即可)
3.String类(重中之重)
3.1 基本概念
3.2 常量池(原理、笔试题)
3.3 常用的方法(练熟、记住)
day12
1.String类(重中之重)
1.1 常用的方法(练熟、记住)
1.2 正则表达式(查手册会用即可)
day13
1.StringBuilder类和StringBuffer类(会用即可)
1.1 基本概念(笔试题)
1.2 常用的方法(练熟)
2.日期相关的类(查手册会用即可)
2.1 Date类
2.2 SimpleDateFormat类
2.3 Calendar类
3.集合类(重点)
3.1 数组和集合的比较(笔试题)
3.2 集合框架
3.3 Collection接口的常用方法(练熟、记住)
day14
1.Collection集合的常用方法(练熟、记住)
2.List集合(重中之重)
2.1 基本概念
2.2 常用的方法(练熟、记住)
2.3 泛型机制
3.Queue集合(重点)
3.1 基本概念
3.2 常用的方法
day15
1.Set集合(重点)
1.1 基本概念
1.2 常用的方法
1.3 元素放入HashSet集合的原理(理解)
1.4 增强版的for循环(for each)
1.5 TreeSet类
2.Map集合(重点)
2.1 基本概念
2.2 常用的方法
day16
1.Map集合(重点)
1.1 常用的方法
2.异常机制(重点、简单)
2.1 基本概念
2.2 异常的分类
2.3 异常的避免
2.4 异常的捕获
2.5 异常的抛出
2.6 自定义异常
3.File类(查手册会用即可)
3.1 基本概念
3.2 常用的方法
day17
1.I/O流
1.1 基本概念
1.2 基本分类
1.3 基本框架
1.4 FileOutputStream类(重中之重)
1.5 FileInputStream类(重中之重)
1.6 DataOutputStream类(会用即可)
1.7 DataInputStream类(会用即可)
1.8 BufferedWriter类(重点)
1.9 BufferedReader类(重点)
1.10 PrintStream类(重点)
day18
1.IO流
1.1 ObjectOutputStream类(重点)
1.2 ObjectInputStream类(重点)
2.线程
2.1 基本概念
2.2 线程的创建(重中之重)
2.3 线程的编号和名称(会用即可)
day19
1.线程的状态和方法
1.1 线程的主要状态(了解、笔试题)
1.2 线程的常用方法(重点)
2.线程的同步机制(重点)
2.1 基本概念
2.2 解决方案
2.3 实现方式
2.4 原理分析(尽量理解)
2.5 死锁(了解)
2.6 Object类中的方法
day20
1.网络编程的常识
1.1 七层网络模型(了解)
1.2 常用的协议(了解)
1.3 IP地址(重点)
1.4 端口号
2.基于tcp协议的编程模型(重点)
2.1 编程模型
2.2 相关类和方法的解析
3.tcp协议和udp协议的比较(笔试题)
3.1 tcp协议
3.2 udp协议
4.基于udp协议的编程模型(会用即可)
4.1 编程模型
4.2 相关类和方法的解析
day21
1.反射机制(尽量掌握、难点、原理)
1.1 基本概念
1.2 Class类
1.3 Constructor类
1.4 Field类
1.5 Method类
1.6 JavaBean的概念(了解)
2.常用的设计原则(记住)
2.1 软件/项目开发的流程
2.2 常用的设计原则
3.常用的设计模式
3.1 基本概念
3.2 基本分类
day22
1.常用的设计模式
2.常用的查找算法(重点)
2.1 线性/顺序查找算法
2.2 二分/折半查找算法
3.常见的排序算法
3.1 冒泡排序算法(重中之重)
3.2 插入排序算法(理解原理)
3.3 选择排序算法(理解原理)
3.4 快速排序算法(重点、难点)




